










Following Microsoft Azure and the Google Cloud Platform, Amazon Web Services today made the much-anticipated plunge into supporting the Cloud Native Computing Foundation’s Kubernetes open source container orchestration engine.
The company also introduced a new managed container service, a new graph database and a “serverless database,” based on the company’s Aurora (MySQL) database architecture. The services and upgrades were introduced by Andy Jassy, AWS CEO, during the company’s annual Re:Invent user conference, held in Las Vegas this week.
Here’s the rundown:
Container Ecosystem
Amazon Elastic Container Service for Kubernetes (EKS): This service will run an upstream version of Kubernetes, with the intent of allowing users to use all the Kubernetes plug-ins and support tools, as well as allowing users to easily move containerized workloads between AWS, other cloud providers and their own data centers.
The company has also added some resiliency support, with the help of Heptio. The company will run Kubernetes across three availability zones, to eliminate single points of failure. Unhealthy masters are automatically detected and replaced. This version of K8s is also integrated with other AWS services such as Elastic Load Balancing, IAM (for authentication), AWS CloudTrail and, for networking, Amazon VPC and AWS PrivateLink.
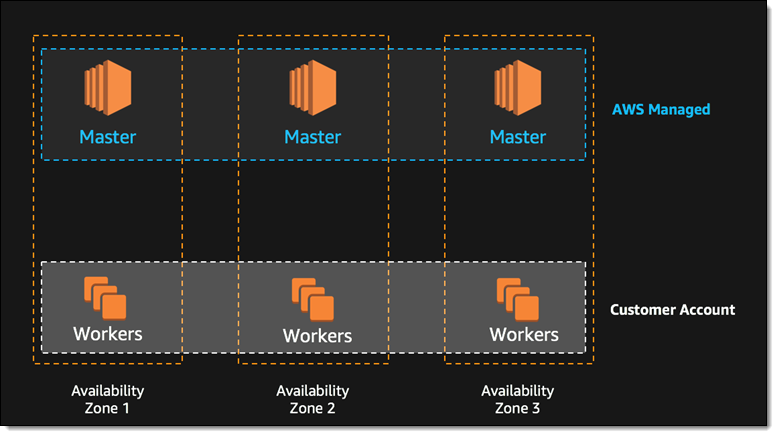
The three masters of AWS EKS.
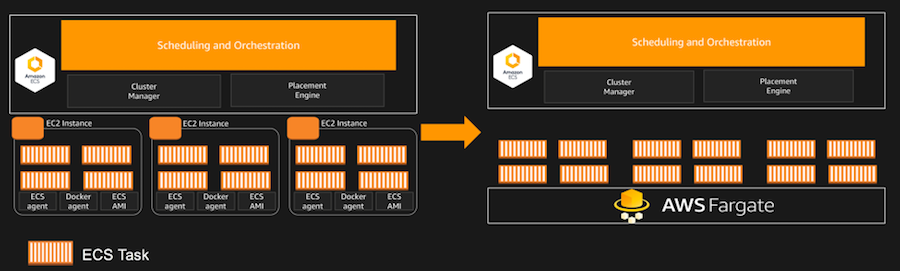
AWS Fargate: While industry observers were expecting some sort of Kubernetes support, the freshly unveiled AWS Fargate service was a bit of a surprise, and perhaps an even more important debut, from the perspective of the enterprise. This service provides a way, according to Jassy, to run containers, through either EKS or AWS’ own in-house Elastic Container Service, without managing the underlying servers or clusters.
“It changes the way you can run containers. People want to run containers on the task level,” Jassy told the audience.
Fargate offers containers in much the same way that AWS Elastic Cloud Compute offers virtual machines, “as a fundamental compute primitive without having to manage the underlying instances,” according to an AWS blog. To build a container image, the user simply specifies the CPU and memory requirements and the networking and authentication policies. Billing will be done on a per-second granularity.
Data Data Data
Aurora Serverless: Aurora now has multi-master, scale-out capability for both reads and writes, meaning a single database can have multiple masters across multiple availability zones. Previously, Aurora only offered multiple masters for reading, so the addition of writing is a step up in offering a truly distributed multi-zone database. A recovery from failure can take as little as 100 milliseconds, making any failures transparent to the user.
“It allows your applications to transparently tolerate failure in any master, even in an entire availability zone,” Jassy said. Single-region, multi-master is available today; multi-region multi-master will be available in early 2018.
AWS has also expanded Aurora in another way: allowing customers to pay for only what they use. This variant, Aurora Serverless, is available in preview.
“It doesn’t require you to provision any database instances. It automatically scales up when the database is busy, it scales back down when it is not. It shuts down when it is not used at all. And you pay only by the second,” Jassy said.
DynamoDB Updates: AWS’ flagship NoSQL database service, DynamoDB, has been updated to a fully multi-region global database, one that can offer the same latency no matter which availability zone the user is tapping into.
It now features global tables — the ability to create tables that get automatically replicated across two or more AWS regions — complete with multi-master writes. This should eliminate all the database admin drudgery of maintaining a replication process.
DynamoDB now also provides the ability to create full backups of tables through a single click, with zero impact on performance. It will also feature, in early 2018, point-in-time restore, down to the exact specified second.
Amazon Neptune is AWS’ entry into the growing graph database market. It is a service that can store billions of relationships, with the ability to query the relationships within milliseconds. It supports the major standard-based stacks for graph querying: the Apache TinkerPop-based property graphs queried with Gremlin, and the Resource Description Framework (RDF) queried with SPARQL.
Also, on the data front, AWS revealed Glacier Select, to supports querying of objects within its archival storage service, Glacier, the first of the major cloud provider to offer this capability, Jassy boasted.
The company also announced a Service Broker for bridging in-house and cloud resources, as well as updates to its spot instance pricing and a number of new machine learning services, which will be discussed in an upcoming post.
Microsoft, Google Cloud and Cloud Native Computing Foundation are sponsors of InApps.
Feature image: On-stage at AWS Re:Invent, AWS CEO Andy Jassy skewers the competition for its greediness.














