










Picture yourself as a software engineer with an up-and-coming Cincinnati-based IT provider called Astronomer. You’ve outfitted your operation with superb provisioning tools to get your customers up-and-running on the latest Amazon cloud services. Particularly, you’re focusing on AWS Lambda for your functionality, CloudWatch for your resource monitoring, Kinesis for real-time data streaming, and Elastic Beanstalk for autoscaling.
You’ve brought your firm into full running operation in a matter of a few months with a team of just five. Things should be going swimmingly. But then you realize a few things: First, the API gateway you’ve tacked onto Lambda is processing upwards of one billion events per month. The scalability of Beanstalk is limited when you’re dealing with multiple clients with individual, unique demands. You’ve been reading up on that open source Kafka ecosystem and it appears richer somehow, making you wonder if Kinesis may only run a subset of what you’re dreaming of.
“We also had product obstacles,” explained Aaron Brongersma, vice president of engineering with data services platform provider Astronomer — the fellow whose shoes you’ve been picturing yourself in.
Speaking at MesosCon 2017 in Los Angeles in mid-September, Brongersma said, “Our customers had issues accessing all of their data. So if you’re a SaaS provider and you want to operationalize someone else’s data warehouse, that becomes a very custom VPN solution — they had to open ports to the public, they had to whitelist IP addresses. So what we found is, we really needed to start doing our work inside of a firewall, or inside of a private network.”
On top of those, Astronomer found itself dealing with these very classic issues: location, location, location.
Cincinnati, Ohio — where Astronomer is headquartered — is at the epicenter of a tectonic shift in the retail and consumer products industry. “Where we’re located, we’re right around the corner from companies like Kroger who are fighting a data war right now with Amazon,” said Brongersma. There’s also the headquarters of Macy’s Inc. department stores, and the parent company of consumer retailers’ most trusted brand provider, Procter & Gamble (P&G).
Like Astronomer, Kroger was hosting many of its assets on AWS. After Amazon acquired nationwide grocer Whole Foods last month in a $14 billion deal and made overtures that it wasn’t stopping there, Kroger found its IT on shaky territory.
“What we’re finding is, there’s a level of apprehension for adopting Amazon-based services,” Brongersma later told InApps Technology. “They could easily get into almost anyone’s space now and disrupt you. No one ever thought that Amazon was going to buy a grocery store, and then they do. We have companies like Procter & Gamble, Kroger, and GE Digital — they’re starting to feel the pain of being cloud-locked.
“When your cloud also becomes your competitor, that adds a ton of friction,” he told us. “You’re not neutral anymore.”
A Time for Forklifts
Instead of helping major enterprises continue to execute their public cloud migrations like leading wildebeests over a cliff, Astronomer realized it had to reverse its business model. Specifically, it needed to “forklift,” as Brongersma put it, his own company’s data engineering platform into customers’ existing premises, converting them into clouds unto themselves, and making them competitive inside their own territories.
“We didn’t want to be limited by any one cloud services provider. So that landed us on [Mesosphere] DC/OS,” he told the MesosCon audience. DC/OS (Data Center Operating System) is a distributed operating system built on the Apache Mesos distributed systems kernel, which manages multiple servers as a single computer.
“We knew that a lot of the components we were using at Astronomer — things like Cassandra and Spark — were first-class citizens in Mesos,” Brongersma continued. “But what we didn’t know is how to get Mesos up-and-running quickly. We were a small engineering team, and we had never really worked on the SMACK stack before.”
By the “SMACK stack,” Brongersma is referring to Spark, Mesos, Akka, Cassandra, and Kafka (not necessarily in that order, but certainly for the sake of the acronym). The SMACK stack uses loosely coupled, open-source tools that are proven to work at scale. In brief, as described by Mesosphere’s Edward Hsu in a post on the Mesosphere blog about the SMACK stack, Spark provides the framework for large-scale data processing; Mesos serves as the distributed systems kernel that provides resourcing and isolation across all the other SMACK stack components; Akka is the “toolkit and runtime to easily create concurrent and distributed apps that are responsive to messages; Cassandra is the distributed database management system and Kafka serves as the “high-throughput, low latency platform for handling real-time feeds with no data loss.”
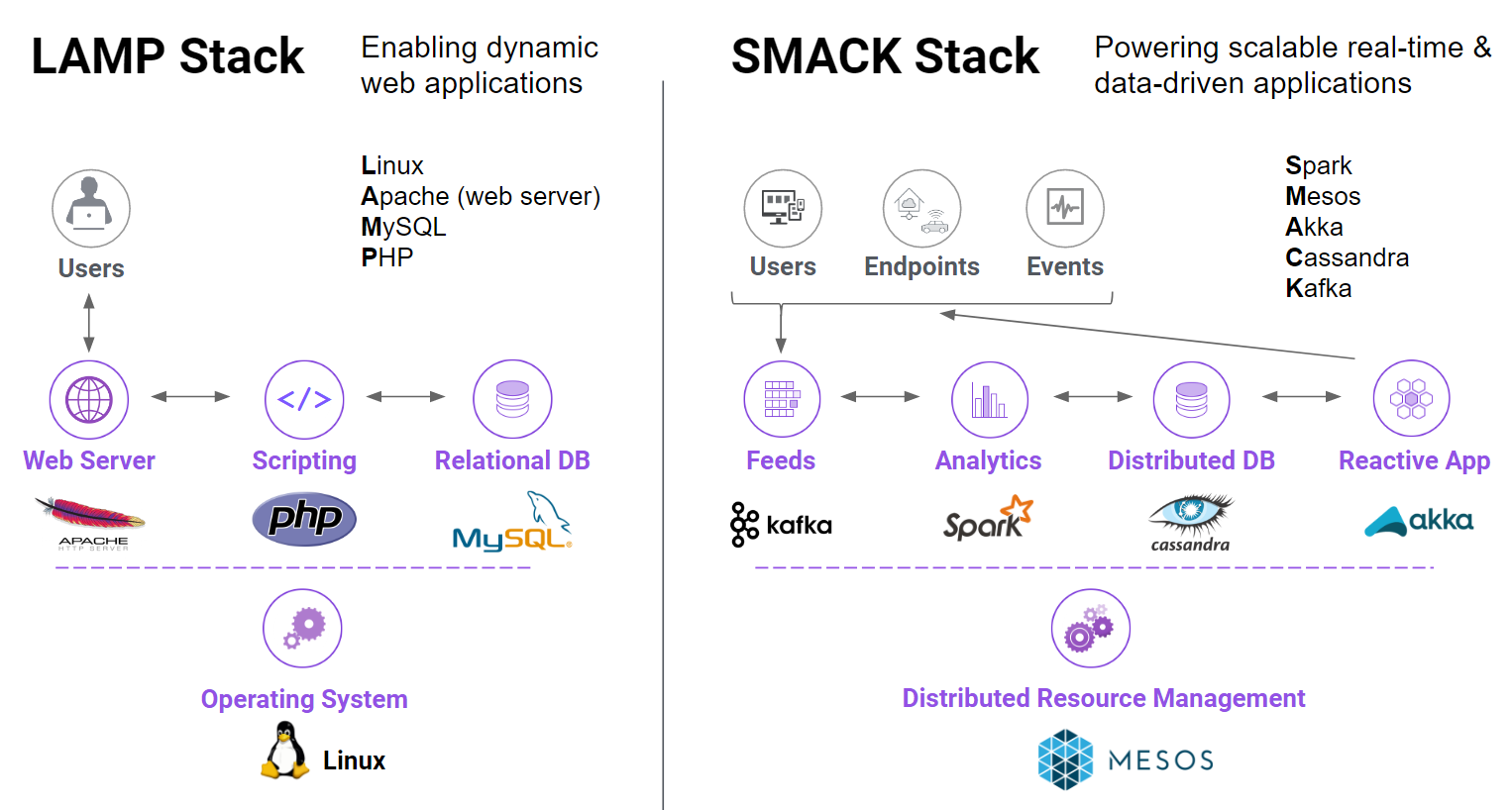
Graphic courtesy of Mesosphere.
Mesosphere’s experience with deploying SMACK on DC/OS, he said, “put us in a position where we were able to deliver the same functionality that we were delivering on Amazon, using Amazon components, in a relatively short timeframe. Bringing in DC/OS brought in a large number of strong opinions, and those strong opinions helped us not have to go reinvent the wheel.”
As DC/OS was first entering the developer space a few years ago, Mesosphere assumed a partnership stance with Amazon along with most every other startup in the cloud development space. But since that time, Mesosphere chief marketing officer Peter Guagenti has been singling out Amazon’s behavior, including at MesosCon, as at the very least, something less than sharing. In a recent contributed piece for Re/code, Guagenti compared the hourly fees AWS collects for its foundational cloud services to a “tax”:
“AWS long ago stopped being about developers purchasing servers. Now it offers hundreds of services — usually, open source tools swiped from public repos, given fancy names and hidden behind proprietary APIs — that are on-demand, by-the-hour components you can plug into your application… If you ever decide to move your application (like, for example, when Amazon becomes a competitor, as they did to other customers such as Netflix), you simply can’t.”
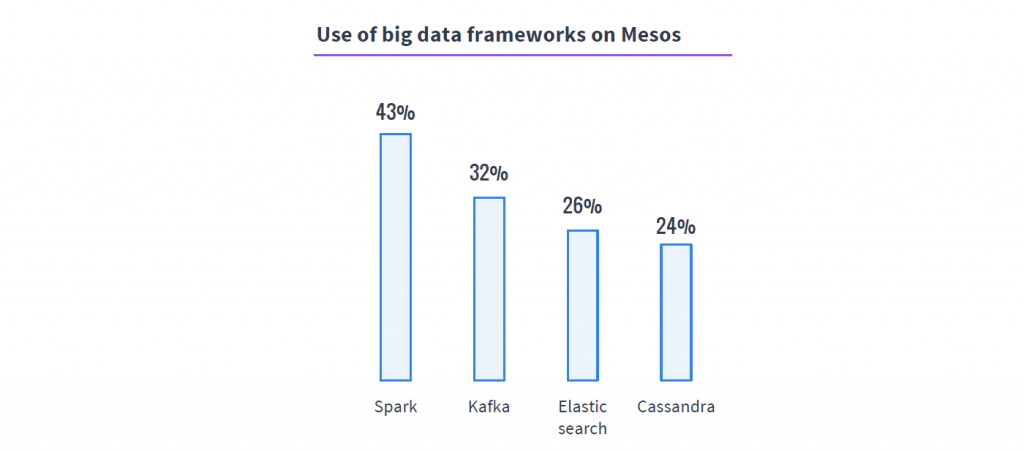
While Astronomer’s customers may have been unwilling to put their faith in Amazon as a global cloud service provider — having just revealed itself to be their worst nightmare in the marketplace — they weren’t much more willing to trust one of its competitors (Google, Microsoft Azure) for the same cloud platform, either. What’s more, organizations with their own data lakes — huge masses of as-yet-unrefined data spanning storage volumes — were discovering that their cost savings from cloud-based storage had already fallen below zero.
“We needed the ability to bring up Spark quickly, so Spark was really our tip-of-the-spear approach,” as Brongersma described it. “That was to replace Amazon’s Elastic MapReduce services. Then right behind Spark came Apache Airflow, which is an open source tool that we’ve adopted and are nurturing. This is a component out of Airbnb, and we found it out of a need to replace an Amazon tool called Simple Workflow.
“Not all Amazon services are created equal,” he continued. “The maturity of these product lines are not always the same. Services like S3, for example, may be battle-hardened and battle-tested, but when you turn around and look at some of the newer, up-and-coming services, you don’t necessarily guarantee that level of durability.”
Simple Workflow was designed to enable developers building high availability jobs to divide and distribute the tasks related to those jobs in parallel and have the status of those jobs be tracked and logged. When Spark is your data engine, though, you need something that enables a workflow model that, in the end, is not so simple, however.
Airflow enables a scheduling model that more adequately maps real-world tasks to the parallel tasks executed by Spark. And because this manner of scheduling is more about the needs of the data than the application, the platform needs a scheduler that does not, like Kubernetes, take the reins and assume control of the entire virtual infrastructure for the application’s sake. That’s why, from Astronomer’s perspective, the Apache Mesos scheduler, and the ecosystem of tools around it, are better suited to this scenario.
“The next thing that we really needed Airflow for was the ability to do our intelligent Redshift loading,” Brongersma told the audience at MesosCon (revealing how Astronomer still uses AWS for storage). “So we guarantee that the data comes in. That also triggers a task that executes a Spark streaming job, and then we can make sure that we can do our schema inference [the ability to “guess” a schema through the organization of input tables]. So we get much better-defined tables when we go inside of a data warehouse.”
Defensibility
Brongersma has extensive experience developing with Ruby on Rails. He believes the strengths of that platform, which it shares with DC/OS, come from a strong set of defaults. An experienced Ruby on Rails developer would learn over time when and where it was appropriate to override those defaults. Similarly, he said, DC/OS quickly operationalized SMACK, limiting operators’ need for manual configuration except in unusual circumstances. For instance, the question of how the stack interoperated with the DNS service, how service discovery would be ironed out, and how containers would be scheduled, did not become issues.
“We can change the direction of the ship and make it our own,” said Brongersma.
In serving the needs of large enterprise customers, Astronomer’s Brongersma explained, an IT provider needs the means to offer defensibility — the way, when necessary, to defend the design and implementation choices it makes. Granted, it might not be defensible or even compliant for Astronomer to make choices outside of Mesosphere’s existing trust model. But the firm does find itself making necessary and non-arbitrary adjustments, especially with clients who still deploy some of their assets on AWS.
“But we have just abstracted all of the Amazon layers away,” said Brongersma. “We’re just running on dumb VMs. And that adds a layer of confidence for our customers. There is a large amount of work to move cloud providers. But if we treat our VMs as dumb VMs, I can go to Azure or Google Compute, or they can go to a data center and we can run inside that data center, and the underlying components don’t disappear or change, nor do they have to rearchitect their entire application.”
As Mesosphere CEO Florian Leibert told InApps Technology, modern customers expect their cloud-based platforms to stitch together their services and data into a cohesive whole. The danger there, however, is that the cloud platform provider can take advantage of that cohesion to drive more products and services, tightening their grip on customers, and locking them into choices they may not be aware of having made.
Neither Microsoft nor Google’s parent company, Alphabet, have competitive stakes in the retail industry. That’s the one distinction that makes Amazon, for certain customers, a less desirable host than it once was. And a certain choice group of those customers resides down the street from Astronomer, in Cincinnati. As Amazon’s business interests become more pronounced, a new battlefront is opening up along the Ohio River.

Mesosphere sponsored this story.
InApps Technology is a wholly owned subsidiary of Insight Partners, an investor in the following companies mentioned in this article: Astronomer.














